We propose XVO, a semi-supervised learning method for training generalized monocular Visual Odometry (VO) models with robust off-the-self operation across diverse datasets and settings. In contrast to standard monocular VO approaches which often study a known calibration within a single dataset, XVO efficiently learns to recover relative pose with real-world scale from visual scene semantics, i.e., without relying on any known camera parameters. We optimize the motion estimation model via self-training from large amounts of unconstrained and heterogeneous dash camera videos available on YouTube. Our key contribution is twofold. First, we empirically demonstrate the benefits of semi-supervised training for learning a general-purpose direct VO regression network. Second, we demonstrate multi-modal supervision, including segmentation, flow, depth, and audio auxiliary prediction tasks, to facilitate generalized representations for the VO task. Specifically, we find audio prediction task to significantly enhance the semi-supervised learning process while alleviating noisy pseudo-labels, particularly in highly dynamic and out-of-domain video data. Our proposed teacher network achieves state-of-the-art performance on the commonly used KITTI benchmark despite no multi-frame optimization or knowledge of camera parameters. Combined with the proposed semi-supervised step, XVO demonstrates off-the-shelf knowledge transfer across diverse conditions on KITTI, nuScenes, and Argoverse without fine-tuning.
Our approach is inspired by how humans learn general representations
through observation of large amouts of multi-modal data,
and the successes witnessed in computer vision
through multi-task frameworks and auxiliary learning.
Humans can flexibly estimate motion in arbitrary conditions through
a general understanding of salient scene properties (e.g., object sizes).
This general understanding is developed over large amounts of perceptual
data, often multi-modal in nature in arbitrary conditions through a general
understanding of salient scene properties.
For instance, cross-modal information processing between audio and video
has been shown to play a role in spatial reasoning and proprioception.
Drawing from this human learning paradigm, our approach leverages extensive
multimodal data through a semi-supervised training process, incorporating
various auxiliary prediction tasks, including segmentation, flow, depth,
and audio, to achieve generalized visual odometry without any camera intrinsic
or extrinsic information in diverse environment under arbitrary conditions.
Our approach is also motivated by the successes witnessed in computer vision
through multi-task frameworks, where auxiliary tasks, in addition to the
primary learning objective, serve as a regulation to reduce the overfitting
and enrich the feature representations.

The figure above illustrates the importance of audio in estimating vehicle acceleration and braking. The frame is consistent with the red arrow marked on the waveform. On the left, the audio amplitude decreases and maintains a low level when the vehicle is going to wait for traffic lights. On the right, the audio experiences many ups and downs associated with acceleration and braking in a narrow urban area.
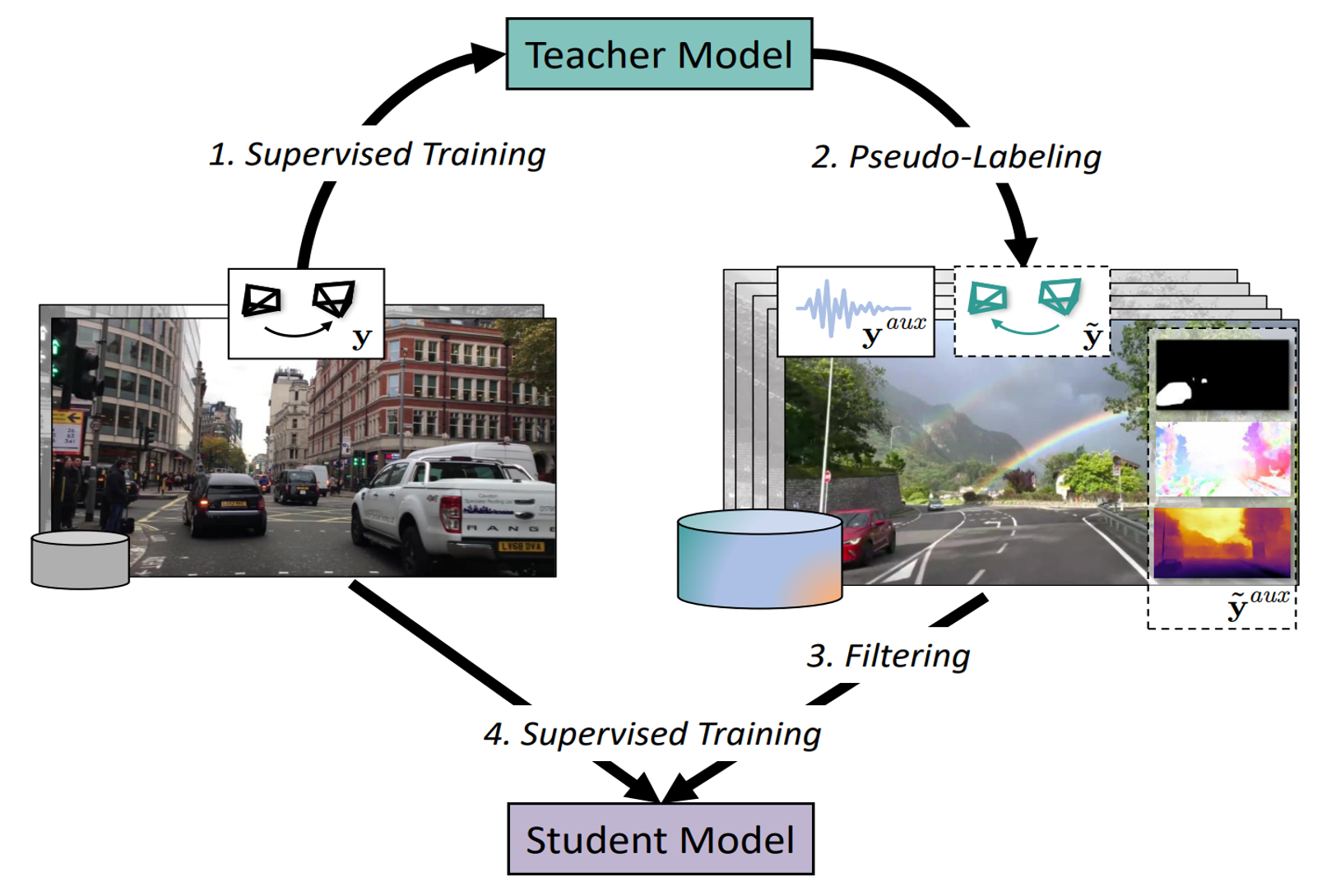
Our proposed framework comprises the following steps: (1) uncertainty-aware training of an initial (i.e., teacher) VO model; (2) pseudo-labeling with the removal of low-confidence and potentially noisy samples; (3) self-training with pseudo-labeled and auxiliary prediction tasks of a robust VO student model. Specifically, we first train an ego-motion prediction teacher model over a small initial dataset, e.g., nuScenes. We then expand the original dataset through pseudo-labeling of in-the-wild videos. After that, we employ multiple auxiliary prediction tasks, including segmentation, flow, depth, and audio, as part of the semi-supervised training process Finally, we leverage uncertainty-based filtering of potentially noisy pseudo labels and train a robust student model.
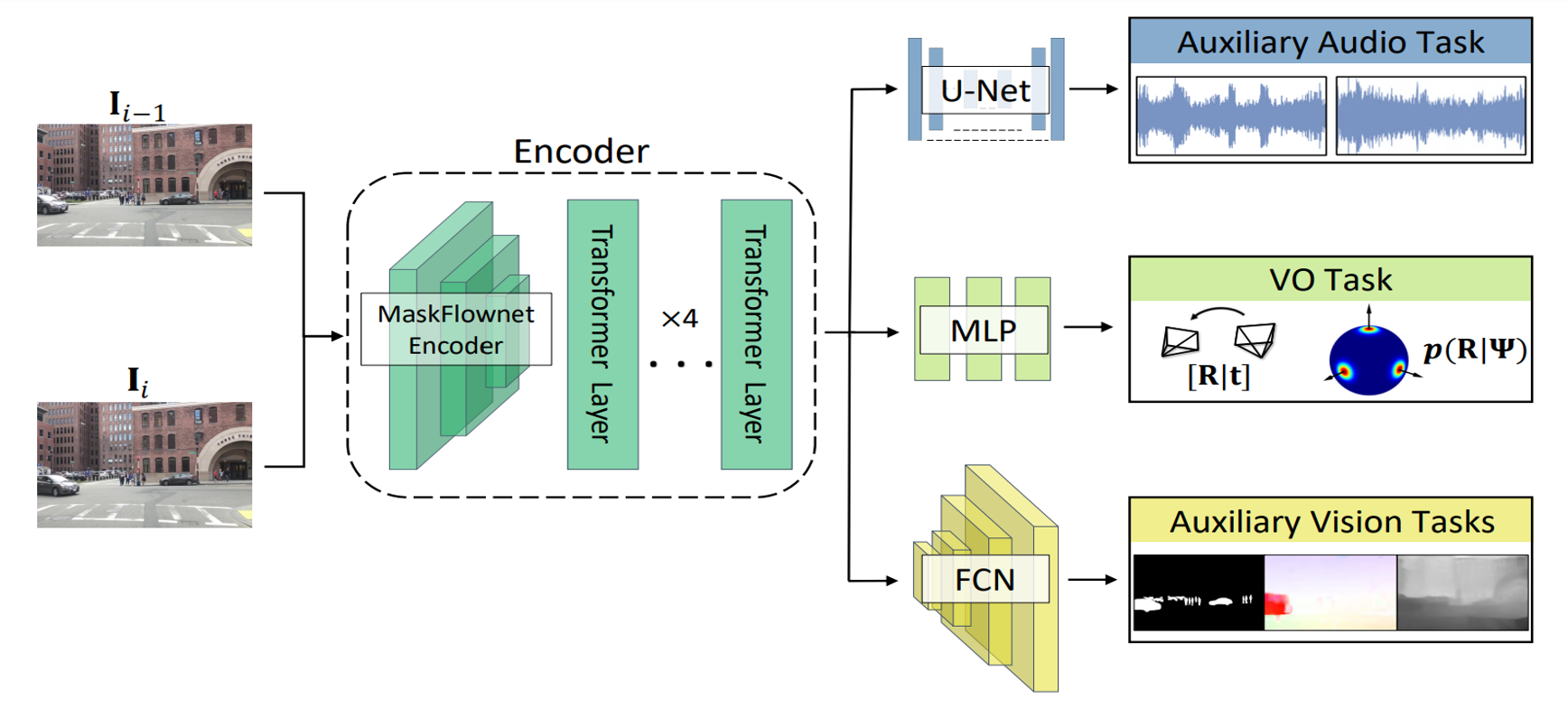
The initial teacher model (used for pseudo-labeling and filtering) encodes two concatenated image frames and predicts relative camera pose and its uncertainty. To learn effective representations for generalized VO at scale, we propose to incorporate supervision from auxiliary but potentially complementary prediction tasks in addition to the generated VO pseudo-labels. Threfore, the complete cross-modal architecture leverages a similar model architecture but with added auxiliary prediction branches with complementary tasks that can further guide self-training, e.g., prediction branches for audio reconstruction, dynamic object segmentation, optical flow, and depth. <\p>
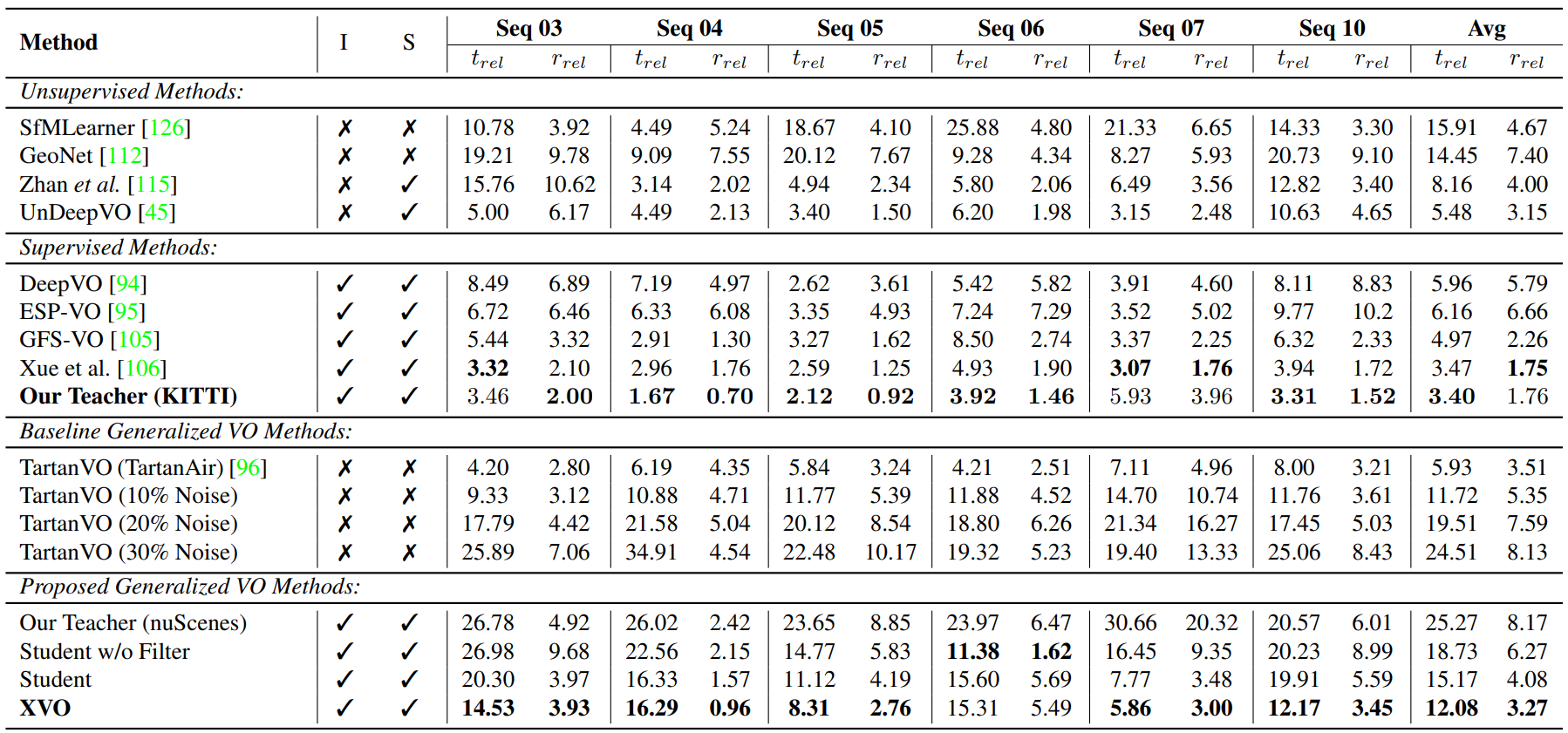
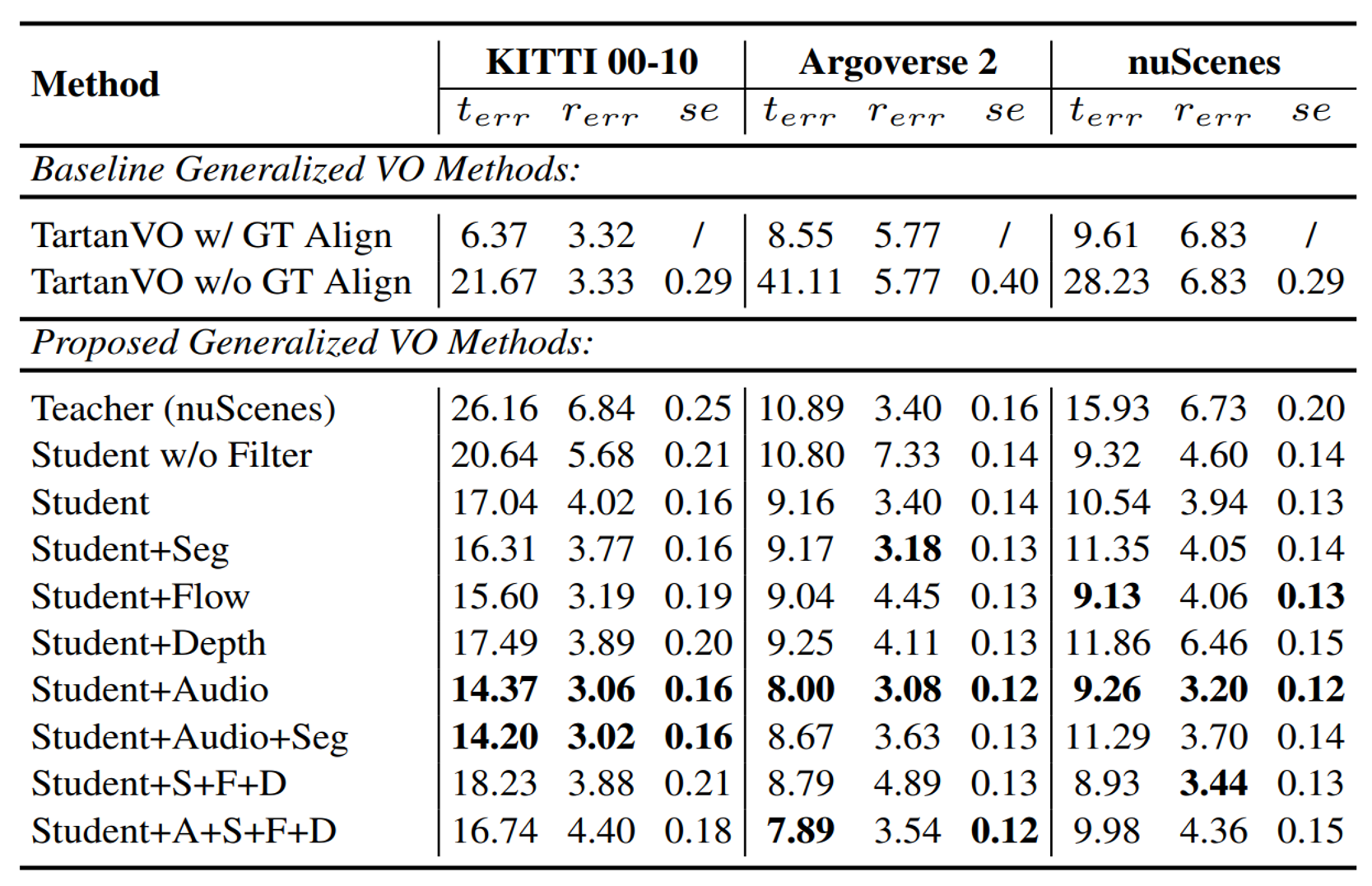
Analysis on the KITTI Benchmark. We abbreviate 'intrinsics-free' as I (i.e., a method which does not assume the intrinsics) and 'real-world scale' as S (i.e., a method is able to recover real-world scale). To ensure meaningful comparison, we categorize models based on supervision type. Firstly, we present unsupervised learning methods, followed by supervised learning methods, then generalized VO methods, and finally our XVO ablation. In the case of TartanVO, we analyze robustness to noise applied to the intrinsics. We train two teacher models: one based on KITTI (as shown in supervised learning approaches) and the other on nuScenes (as displayed at the end of the Table with ablations).
Average Quantitative Results across Datasets. We test on KITTI (sequences 00-10), Argoverse 2, and the unseen regions in nuScenes. All results are the average over all scenes. We present translation error, rotation error and scale error. Approaches such as TartanVO do not estimate real-world scale but may be aligned with ground truth (GT) scale in evaluation. A, S, F, D are the abbreviation of Audio, Seg, Flow, Depth.
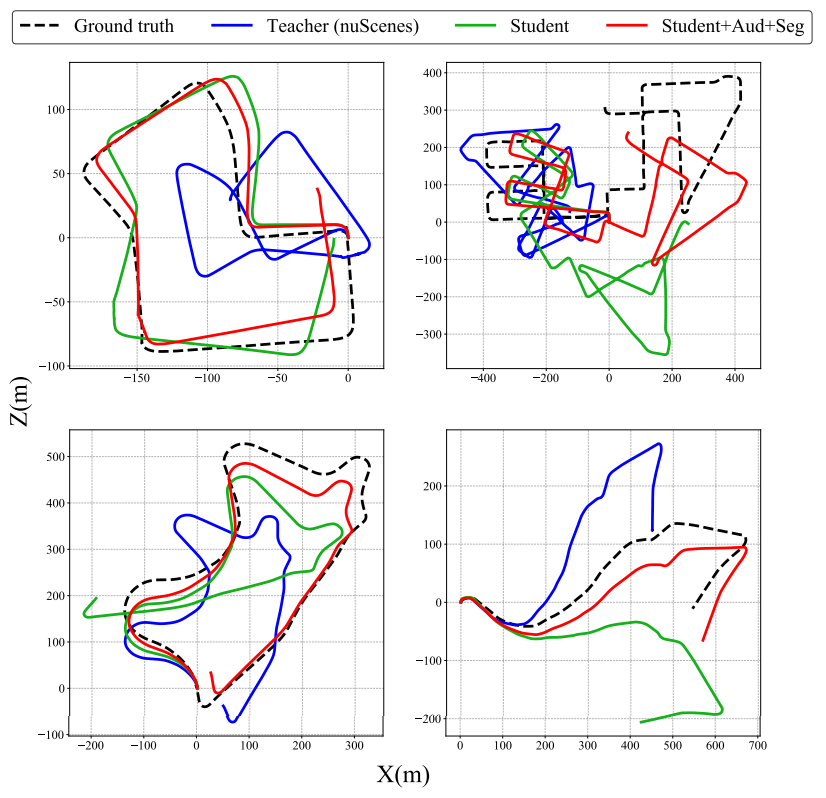
Qualitative Analysis on KITTI.. We find that incorporating audio and segmentation tasks as part of the semi-supervised learning process significantly improves ego-pose estimation on KITTI.